Convolutional Neural Network
udacity self driving car의 computer vision 부분을 통해 학습한 내용을 정리한 페이지 입니다.
개요
합성곱 신경망 (Convolutional Neural Network)은 이미지를 학습하는데 호율적인 알고리즘입니다. 기존의 방식인 fully connected layer는 inputdata가 커지면 커질수록 학습하여야 할 파라미터가 급격히 늘어나게 됩니다. 이 탓에 이미지와 같이 inputdata가 큰 경우 학습이 느려지게 됩니다. Convolutional Neural Network는 이러한 단점을 보안하고, 더 효율적으로 이미지를 학습할 수 있습니다.
CNN - 사람이 이미지를 인식할 때
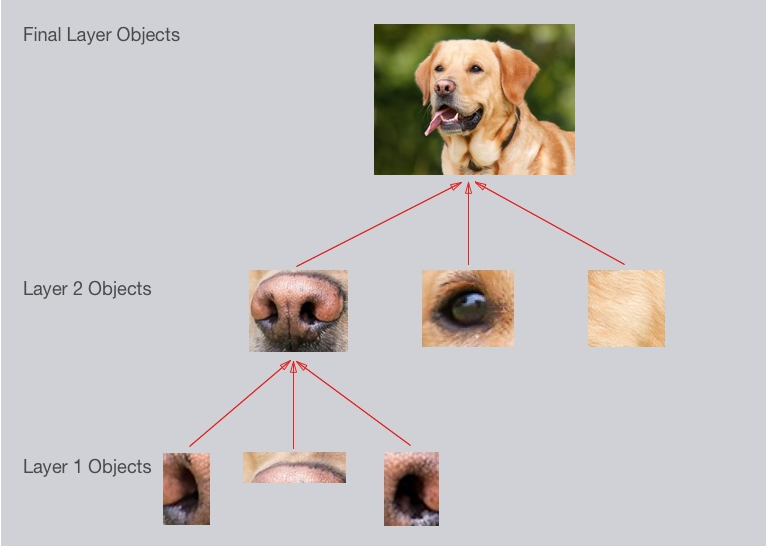
cnn에 대하여 먼저 설명하기 전에, 사람이 이미지를 인식하는 방법을 설명하도록 하겠습니다. 사람이 이미지를 인식하는 방법은 그림과 같이 간단한 패턴을 통해 복잡한 물체를 인식하는 방식입니다. 먼저 점과 선을 인식하고, 그에 따른 도형(눈, 코, 귀 등)을 인식한 후, 그에 해당하는 물체를 인식하게 됩니다. CNN은 사람이 이미지를 인식하는 방법과 유사하게 작동합니다.
CNN - 필터
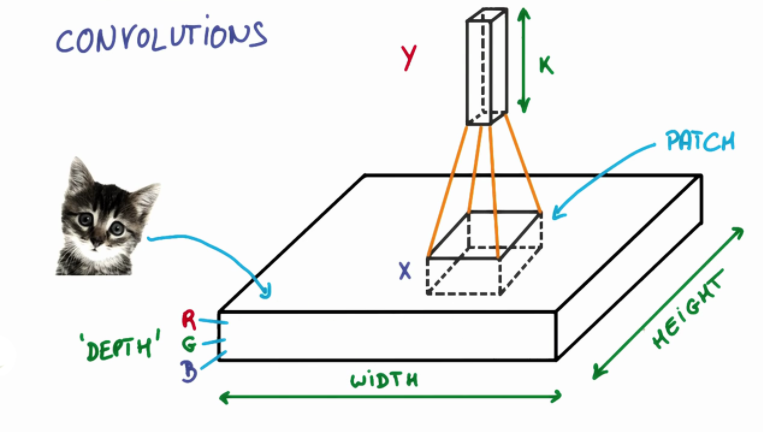
CNN은 다음 그림과 같이 작동한다고 보시면 됩니다. 이미지에 해당하는 정보를 필터가 일정 간격씩 훑고 지나가며 파라미터를 학습합니다. 이러한 필터는 각 ‘층' 마다 파라미터가 나뉘어져 있습니다. 또한 이러한 층은 각 inputdata의 ‘특징(눈, 코, 귀와 같은)'을 상징합니다.
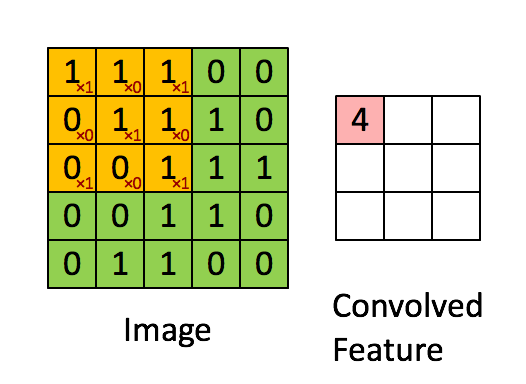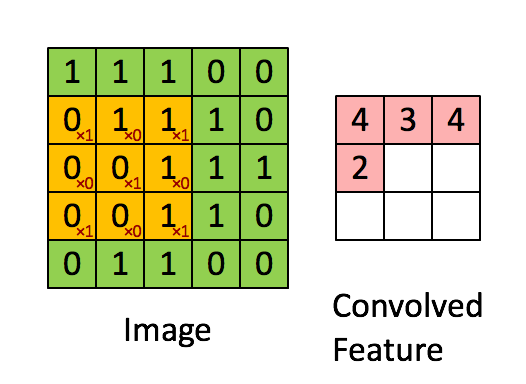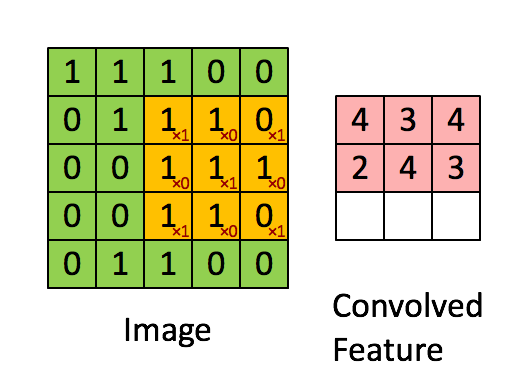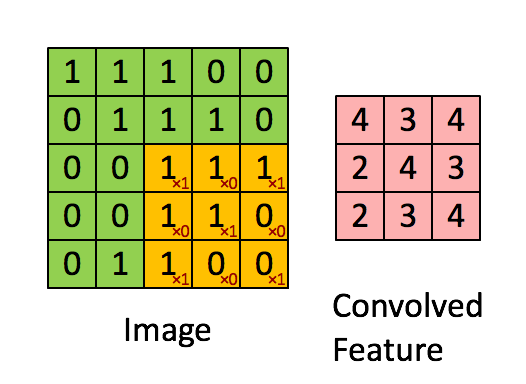
한 층의 필터를 통해 input에서 output을 계산하는 과정입니다. 그림과 같이 주황색으로 표시된 필터는 가중치가 변하지 않습니다. 즉 fully connected 에서는 모든 가중치가 학습하면서 달라지나, CNN에서는 한 필터의 가중치가 변하지 않기 때문에 파라미터 수도 적어지고, 이미지 검출의 위치 불변성 또한 얻을 수 있습니다.
CNN - 위치 불변성

위치 불변성 (translation invariance)은 이미지의 위치가 달라도 분류는 같아야 하는 것을 뜻합니다. 그림과 같이 고양이가 어떤 위치에 있는지는 상관없이 고양이로 분류하여야 합니다. CNN의 필터는 위치에 관계없이 파라미터가 동일하므로(왼쪽 위를 input으로 하나 오른쪽 아래를 input으로 하나 가중치는 같으므로) 위치 불변성을 지킬 수 있습니다.
CNN - pooling
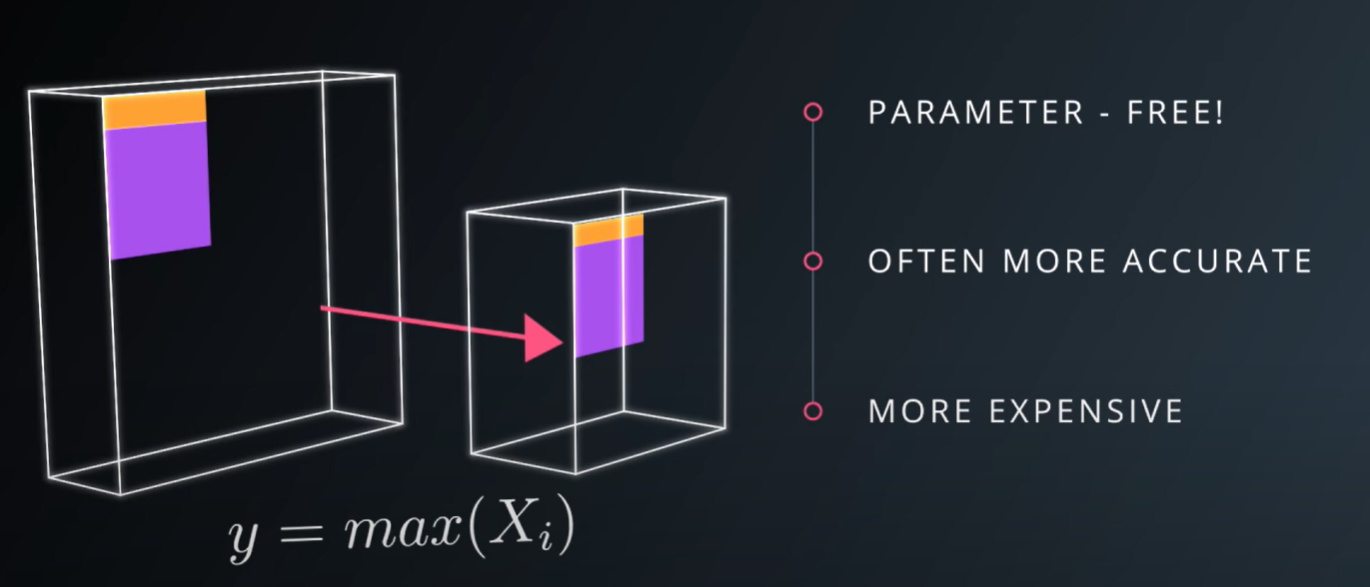
pooling은 입력데이터의 down sampling을 위해 사용합니다. convolution만 이용할 경우 학습할 파라미터가 매우 증가하기 때문에 이를 줄여주기 위해 pooling으로 입력데이터를 작게 만들 수 있습니다. 특히 maxpooling을 이용하면 입력데이터의 가장 두드러지는 특징점만을 사용할 수 있기 때문에 과적합을 방지하고 더 정확한 결과를 얻을 수 있습니다. 그러나 근래에 들어서 학습시킬 수 있는 dataset이 증가하여 과적합보다는 과소적합이 더 중요해졌고, maxpooling으로 인해 손실되는 특징점들이 있기 때문에 pooling 보다는 1*1 convolution이 더 선호되는 추세입니다.
CNN 최종구성
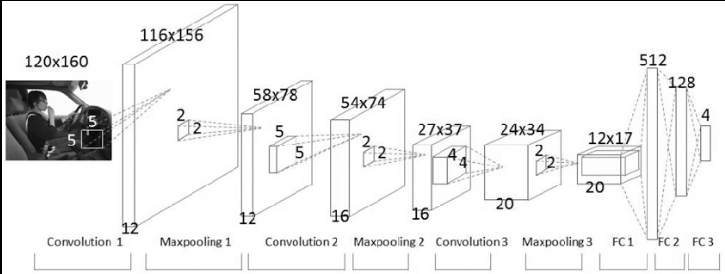
기본적인 CNN의 최종 구성은 다음과 같습니다.